파이토치
[파이토치] LSTM / GRU
알 수 없는 사용자
2022. 2. 14. 13:41
- There are two other popular recurrent layer: LSTM and GRU.
- SimpleRNN is difficult to learn long-term dependencies.
- This is due to the vanishing gradient problem.
- Long Short-Term Memory (LSTM)
- proposed by Hochreiter and Schmidhuber in 1997
- It adds a way to carry information across many timesteps.



class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, sequence_length, num_layers, device):
super(LSTM, self).__init__()
self.device = device
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size*sequence_length, 1)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size()[0], self.hidden_size).to(self.device)
c0 = torch.zeros(self.num_layers, x.size()[0], self.hidden_size).to(self.device) # cell state가 추가되었다.
out, _ = self.lstm(x, (h0, c0)) # output, (hn, cn): cell state와 hidden state만 반환 (순서쌍 형태로)
out = out.reshape(out.shape[0], -1) # <- state 추가
out = self.fc(out)
return out
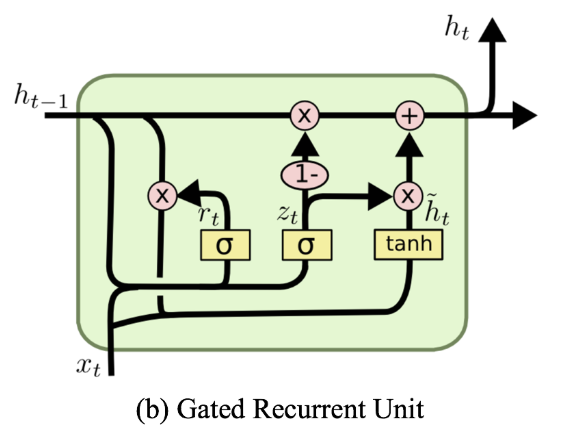
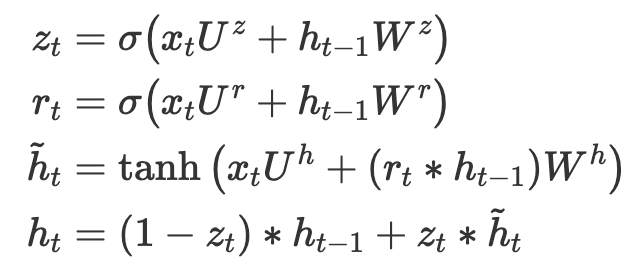
class GRU(nn.Module):
def __init__(self, input_size, hidden_size, sequence_length, num_layers, device):
super(GRU, self).__init__()
self.device = device
self.hidden_size = hidden_size
self.num_layers = num_layers
self.gru = nn.GRU(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size*sequence_length, 1)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size()[0], self.hidden_size).to(self.device)
out, _ = self.gru(x, h0)
out = out.reshape(out.shape[0], -1) # <- state 추가
out = self.fc(out)
return out
