오늘 읽어 볼 논문은 2019년에 IEEE Transactions on Industrial Informations에서 발표된 An Incremental Deep Convolutional Computation Model for Feature Learning on Industrial Big Data라는 논문입니다. Dynamic한 big data data steram환경에서 어떠한 방식으로 robust한 모델을 구성할 수 있을지에 중점을 두면서 내용을 읽어보시면 될것같습니다.
딥러닝 아키텍처는 빅데이터 처리를 위해 두가지 scheme으로 분류될 수 있습니다. 첫째는 advanced한 computational techniques를 활용하는 것이고, 둘째는 중요한 feature를 추출하여 robutst한 모델을 구축하는것에 중점을 두며 적은 training cost를 이용함과 동시에 이기종 데이터의 feature learning을위해 제안되었다. 그 중 Deep Convolutional Computation Model이 기존의 CNN모델을 tensor space로 확장함으로써 robust한 모델을 구축하였지만 static한 특성때문에 빠른속도로 생성되는 데이터에 따른 변화 반영이 어렵다는 한계가 존재하였습니다. Incremental한 learning 방법은 새롭게 생성된 데이터만을 이용해서 historical knowledge를 최소화함과 동시에 새로운 패턴을 반영하는 것을 목표로 합니다. 많은 제안된 Incremental 알고리즘은 크게 대표적으로 두가지 방식으로 분류될수 있는데 이는 parameter-incremental 방식과 structure-incremental 방식입니다.
먼저 parameter-incremental algorithm은 훈련된 모델의 가중치와 bias를 수정하는 몇가지 새로운 constraint rules을 design하여 sequential한 방식으로 모델에 공급되는 새로운 인풋을 반영합니다. 전체 데이터 세트를 메모리에 유지할 필요가 없다는 특성에 따라 Real-time massive data applications에 적합합니다. Structure incremental 알고리즘은 새로운 입력의 특징을 포착하는 새로운 multilayer 퍼셉트론이 네트워크 구조를 업데이트할때 pre-trained된 classifier의 앙상블에 추가됩니다.이러한 종류의 알고리즘은 주로 Dynamic applications에서 feature learning에 적합합니다. 하지만 이러한 알고리즘들은 traditional classification 방식을 사용하며 DCCM구조에 적합하지 않기 때문에 본 논문에서는 DCCM 모델을diverse한 빅데이터 stream에서 incremental한 방식으로 개선하기를 목표로 합니다.
제안하는 Incremental DCCM은 heterogeneous한 feature를 capture하여 기존에 knowledge에 통합하는 방식으로 설계되었습니다. 먼저 parameter-incremental learning에서는 incremental learning의 학습속도를 위해 initial increments를 위한 새로운 loss function을 정의하여 계산합니다. 이 loss function은 adaption과 preservation 2가지 측면에서의 성능을 모두 반영합니다. 동시에 새로운 dropout 방식이 채택되었는데요. 앞서 언급한 두가지 측면에서의 성능을 추가로 뒷받침하기 위해 제안되었습니다. 이때 fully connected layer에서의 각각의 텐서 뉴런들을 3개의 하위집합으로 그룹화하여 idle한 뉴런의 새로운 패턴에 대한 학습을 최대한 활용하기 위해 서로 다른 switch probability를 가지게 됩니다.
두번째 structure-incremental learning에서는 tensor convolutional layer, pooling layer, and Fully Connected layers가 모두 과거정보를 transfer할 수있도록 새로운 rule을 설계하였습니다. 또한 0의 weight값을 가지는 가상 뉴런을 업데이트 과정에서 사용하여 텐서의 multidot product, convolution and pooling의 계산을 보장하였습니다. Tensor space로의 dropout strategy를 확장하여 DCCM모델의 robustness를 향상 하고자 하였습니다.
먼저 앞서 계속해서 언급되었던 Deep Convolutional Computation Model, 즉 DCCM에 대해서 설명하겠습니다. 이 모델은 이기종 데이터의 feature engineering을 위해서 기존의 CNN모델을 텐서 space로 확장시킨 모델입니다. 이러한 tensor representation은 각각의 heterogeneous한 object의 non-linear한 관계를 capture하는데 사용됩니다. 이러한 tensor 구조에 기반하여 parameter를 공유하는 tensor convolution이 정의되었습니다. Fig. 1에 표현된 순서대로 Tensor convolution, tensor pooling, tensor multidot product를 순서를 통해 학습이 이루어지게되는 것입니다.그후 parameter 조정을 위해 오른쪽 그림의 High-order back-propagation 알고리즘이 사용됩니다. 보시면 forward pass의 반대방향으로 역전파가 이루어 지게되는것을 확인할 수 있습니다.
Drop-out regularization strategy에 대해서 생소하신분들을 위해 간략하게 설명하자면 훈련하는 동안 무작위로 네트워크 층의 일부 출력 특성을 제외하는 것입니다. 따라서 얼마나 더 많은 유닛이 활성화 될지를 결정하는 layer라고 보면 됩니다. 이때 중요한점은 테스트 단계에서는 어떠한 유닛도 드롭아웃 되지 않아야하며 설정한 드롭아웃 비유로 출력을 낮추어 주어야합니다. 만약 0.5를 drop out rate로 설정했다면 테스트 데이터를 0.5배만큼 스케일을 조정해야하는것 입니다.
기존의 DCCM모델은 이기종 데이터 상의 feature를 효과적으로 추출해낼수는 있었지만, dynamic한 빅데이터 환경의 적용은 한계가 있었습니다. 따라서 본 논문에서는 Incremental DCCM을 제안하는데요, 앞서 말한 두가지 알고리즘을 사용합니다. 먼저 parameter incremental learning 알고리즘에 대해서 설명드리겠습니다. 이 알고리즘은 1) Initial increment compuation과 2) Incremental training두가지 stage를 포함합니다.
먼저 initial incremental computation에서는 초기의 parameter 증감분이 새로운 loss function을 도입하여 속도를 증가시킴과 동시에 새로운 데이터의 adaption과 기존의 preservation을 목적으로 하여 계산됩니다. Fig. 2의 (a)와 오른쪽 수식을 참고해서 설명드리겠습니다. 먼저 θ는 historical knowledge를 나타냅니다. 그리고 Δθ는 새로운 데이터에 의해 계산된 initial parameter increment를 나타냅니다. 이를 계산하기 위해서 simplified된 loss function을 활용합니다. 이 loss function은 adaption, 즉 postprediction loss와 preservation (deformation) loss를 활용합니다. 새로운 (x,y)쌍의 데이터 샘플이 주어졌을때 y와 update된 세타 더하기 델타세타 파라메터를 이용하여 추출된 output을 비교한것이 adaption loss로 활용이 되고, preservation 을 측정하기위해서 updated된 아웃풋과 초기의 아웃풋 사이의 l2-normalization 값을 활용합니다. Parameter increment가 계산되면 (5)번 수식에 따라서 tensor parameter increment를 반영합니다.
2번째 stage인 incremental training에서는 dropout- training과 final fine-tuning 두가지 방법을 채택합니다. 먼저 dropout에서는 fully connected layer에서 idle한 노들이 최대한 새로운 정보를 습득하는 식으로 학습이 이루어집니다. 이를 위해 denselayer의 tensor뉴런들을 3가지 하위 집합으로 분류하였습니다. 각 하위 집합에 속한 뉴런들은 베르누이 분포를 따르는 pi라는 drop out확률을 가지게 됩니다. 이때 idle한 뉴런에는 large probability를 assign하고 과거 knowledge를 포함하는 뉴런들에게는 낮은 확률을 assign함으로써 효율적인 학습이 이루어지게됩니다. 다른 하위 집합에 속한 뉴런들은 feature 학습시 다른 역할을 수행합니다. WA는 새로운 데이터에 대한 학습, WB는 대부분지식 보존, Wc는 speical examples 정보 처리에 중점을 둡니다. 따라서 학습이 이루어질때도 WA에 중점적으로 학습이 이루어져야하며 WB는 낮은 확률을 가져야하고 WC는 WB의 subspace에 max-norm기준으로 매핑되어야합니다. 여기서 max-norm이란 벡터 성분들의 절대값중에서 가장 큰값으로 거리가 계산되어집니다. 각 그룹에 대한 probability가 assign되면 1과 0으로 구성된 mask tensor를 생성하고 이를 initial parameter increment과 tensor convolution computation을 수행한후에 업데이트 합니다. 이렇게 생성된 post weight값을 이용하여 input tensor와 multidot product를 수행하고 mask tensor를 곱합니다.최종적으로 fully connected layer에 대한 fine tunning이 이루어 지게됩니다.
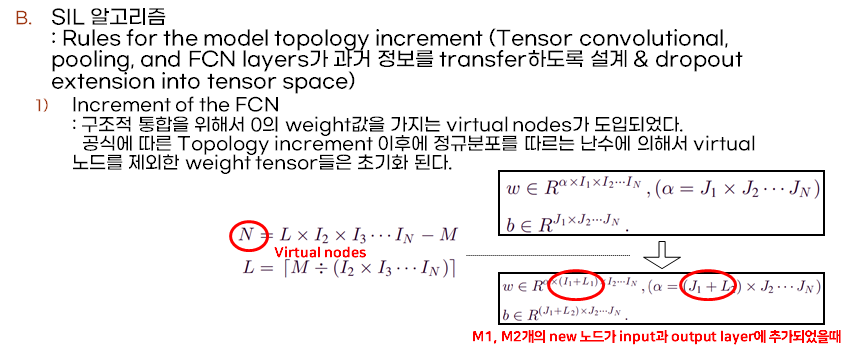
Structure incremental algorithm은 incremental하게 feature를 학습하기 위해서 고안되었습니다. 이 알고리즘은 모델 topology의 increment를 위한 룰을 설계하여 과거 정보를 전이하도록 합니다. 또한 dropout 을 tensor space로 확장하여 모델의 robustness를 보장하고자 하였습니다. 먼저 fully connected network에서의 increment 측면에서의 SIL알고리즘을 설명하겠습니다. Tensor fully connected network의 특성상 layer에 추가하는 뉴럴 노드의 개수를 제한하는데요,이때 structure integrality를 유지하기위해서 0의 weight를 가지는 가상노드를 도입합니다. 예시로 input과 output을 위한 2개의 fcn layer가 있다고 가정하겠습니다. Input feature를 I1, I2, ... IN, output feature를 J1, J2, ... JN이라고 두었을때weight 와 bias는 위의 오른쪽그림과 같이 표현됩니다. 이때 새로 m개의 뉴럴 노드가 input layer에 추가된경우, n개의 가상 노드가 input layer에 통합되어 네트워크의 구조를 유지합니다. N을 구하는 수식은 다음 왼쪽 그림과 같습니다. 이를 integral function에 적용하여 L을 구하고 네트워크 파라메타를 업데이트 합니다. 이때 m1개, m2개의 새로운 노드가 각각 input과 output layer에 추가되었을때 업데이트된 네트워크의 파라메터들은 다음 오른쪽 아래 그림과 같이 표현됩니다.
다음은 Constrained network에서의 increment 입니다. Incremental한 네트워크의 topology는 convolutional이나 pooling layer에서의 kernel에 의해서 표현됩니다. 하지만 여기서는 기존의 커널은 기존 과거 데이터의 유실없이 새로운 데이터에 대한 unknown feature를 반영하기 어렵습니다. 왼쪽그림은 기존의 네트워크의 topology를 나타내는 수식입니다. Input feature layer를 변화하지 않으면서 새로운 tensor convolutional kernel이 subkernel로 통합되어 새로운 output feature map을 만들게 됩니다. 동시에 새로운 tensor pooling kernel이 tensor pooling layer에서 사용됩니다. 마지막으로 drop out을 통해 structure-incremental한 dccm 모델을 구성하고 모델의 robustness를 높이고자 하였습니다.
다음은 실험의 구성과 결과에 대해서 간략하게 설명하도록 하겠습니다. 논문에서는 CIFAR와 CUAVE데이터를 활용해서 Incremental DCCM의 성능을 Parameter-incremental computation algorithm과 High order backpropagation알고리즘과 비교하여 분석하였습니다. 실험에서는 PIC는 Dccm의 fcn layer에서 활용되었으며 Incremental DCCM과의 비교를 통해서 parameter-incremental 방식의 성능을 평가하였습니다. HBP(High-order Back-propagation Algorithm)은이기종 데이터에 대해 학습을 하기 위해서 제안된 알고리즘이며 이는 IncrementalDCCM과의 비교를 통해서 structure incrmental 방식의 성능을 평가하기 위해 사용되었습니다.
먼저 parameter incremental deep convolutional compuation model, 줄여서 PIDCCM에 대한 성능평가를 위해서 CIFAR데이터를 이용해서 실험을 진행했습니다. 데이터는 총 4가지 subset으로 나누어서 실험을 진행하였고 첫번째 subset은 총 20개의 superclass에 대해서 각각 4개의 subclass를 포함하도록 구성하였고 2번째 subset은 담은 subclass에 대한 정보를 포함하였습니다. 3번째는 1과 동일한 subclass를 포함하여 preservation에 대한 성능을 평가하고자 하였고 4번째는 2와 동일한 subclass를 포함하여 adaption에 대한 성능을 평가하고자 하였습니다. 첫번째 그림은 pidccm의 adaption성능을 평가하기위해서 subset4에 수행되었습니다. 그림에서 보시다시피 DCCM에 의한 성능이 다른 모델에 비해 낮은것을 알수있습니다. 즉, traditional 한 static모델은 subset2에 대한 새로운 패턴을 학습하지못하는 것입니다. 이와는 다르게, incremental한 모델들은 subset2를 반영할 수 있습니다. 따라서 subset4에 대해서 높은 classification accuracy를 보여줍니다. 또한 여기서 알수있는 점은 PIL에 의해서 수행된 결과가 PIC모델에 비해 높다는 점입니다. 이는 Neuron-level과 Global-level의 preservation사이의 loss function의 approximation이 새로운 인풋의 feature에 대하여 deviation를 주었으며 improve된 dropout이 새로운 knowledge에 대한 학습을 가능하게 했기 때문입니다. 또한 그래프를 보시면 DCCM-3으로표시되어 전체데이터를 가지고 학습된 모델과 거의 유사한 성능을 냈다는점에 기반하여 제안하는 PIL method는 adaption의 관점에서 높은 성능을 내었다는 점을 증명합니다. 또한 preservation 결과를 보시면 PIL방식이 여전히 PIC에 비해서 높은 성능을 내는것을 확인할수있고 이는 probability의 assignment에 따른 weight의 protection과 fine-tuning에 의해서 나온 결과로 해석할 수 있습니다. 역시 마찬가지로 DCCM-3에 미치지는 못하지만 근사한 preservation관점에서 높은 성능을 내는것을 알수있습니다. 요약하자면 pidccm은 다른 incremental모델에 비해 학습시간이 조금더 소요되긴하였지만 adaption과 preservation에서 높은 성능을 보였습니다.
Structure-incremental deep convolutional model 줄여서 SIDCCM의 성능을 검증하기위해서 CUAVE 데이터셋을 사용하습니다. 여기에는 36명의 화자에 대한 정보가 있는데 홀수번쨰의 화자는 train데이터에 사용되었고 나머지는 모델을 평가하는데 사용되었습니다. 마찬가지로 adaption preservation trainng time 세가지 측면에서의 평가를 dnlgtoj 데이터를 4가지 subset으로 나누었습니다. Subset1은 0-7까지의 label을 가지고있는 obejcts , subset 2는 나머지 8,9를 포함하는 objects, subset 3은 subset1과 동일한 라벨을 가지는 데이터,subset4는 subset2와 동일한 라벨을 가지는 데이터로 구성하였습니다. SIDCCM의 adaption 성능은 가장왼쪽 그래프에서 알수있듯이SIL이 DCCM-1에 비해서 높은 성능을 보여줍니다. 또한 DCCM-2과 거의 근사한 performance를 보여줍니다. B그림은 preservation results를 보입니다. 여기서 sil방식은 DCCM-3와 마찬가지로 parameter generalization이 잘되어있다는 점을 알수있습니다. 또한 4번째 experiment에서 보다시피 dropout 전략을 tensor space로 확장시킴으로써 모델 parameter들을 머 generalize하는데 도움을 주는것을 알 수 있습니다. 마지막은 convergence time의 관점에서 DCCM-SIL에 비해서 학습시간이 현저히 작음을 알 수 있습니다. 두가지 모델은 동일하게 전체데이터를 활용하여 학습되었지만 SIL 모델에서 historical data는 새로운 지식과 과거 지식을 병합하는데 사용한 반면, DCCM-2모델에서는 전체데이터를 이용해서 새로운 parameter에 대한 학습을 진행하였기 때문입니다. 결론적으로 SIDCCM또한 세가지 관점에서 모두 best performance를 보임을 뒷받침하며 제안하는 방식의 효과성을 보여줍니다.
< IMPRESSION >
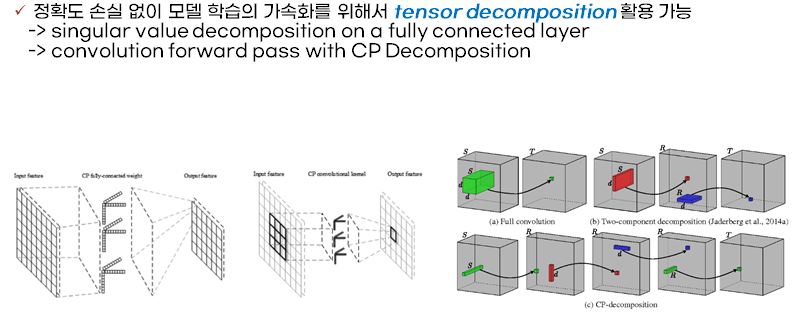
논문에서 제안한것처럼 parameter incremental learning 알고리즘이나 structure incremental learning알고리즘은 새로운 변화의 반영에 있어서 유의미한 결과를 보여줍니다. 하지만 이를 위해서는 대량의 parameter가 필요하므로 real-time processing에 한계가 존재합니다. 이를 위해서 tensor network과 decomposition과 같은 기술이 채택되어 모델을압축하는 기법의 도입이 유용할것이라고 논문에서도 future work로써 언급합니다. 특이값분해를 fully connected layer에서 활용하여 weight의 개수를 감소시킬수도 있으며 convolution computation에서 cp-decomposition을 활용해서 depthwise separable convolutions에 대한 efficient implementation이 가능하였습니다. 관련된 methodology를 찾아보면서 정리한 방법론과 연구에 관한 별도의 링크로 다음과 같습니다[1][2][3][4]. 추후 realtime한 incremental application을 구성할때 이러한 알고리즘을 고려하여 모델을 구성하여 모델의 처리량을 늘림과 동시에 generalized된 feature extraction을 고려해야할 필요성이 있어보입니다. 또한 본 논문에서는 parameter incremental learning알고리즘과structure incremental learning알고리즘을 통합하여 모델을 구성하고 실험을 수행한것이 아닌 각 개별적인 요소에 대해서 서술하고 그 performance를 비교분석하였습니다. 따라서 두가지 알고리즘을 통합적으로 하나의 모델에 구현하고 평가하는 방식을 구현하는것 또한 추후 시도해볼만한 의미있는 연구가 될 것이라고 생각합니다.
[3] Gao, Jing, Peng Li, and Zhikui Chen. "A canonical polyadic deep convolutional computation model for big data feature learning in Internet of Things." Future Generation Computer Systems 99 (2019): 508-516.
[4] Bacciu, Davide, and Danilo P. Mandic. "Tensor decompositions in deep learning."arXiv preprint arXiv:2002.11835(2020).
## '컨테이너 인프라 환경 구축을 위한 쿠버네티스/도커' 책을 공부하며 정리한 글입니다.
컨테이너 인프라
컨테이너 인프라 환경은 말 그대로 컨테이너를 중심으로 구성된 인프라 환경입니다.
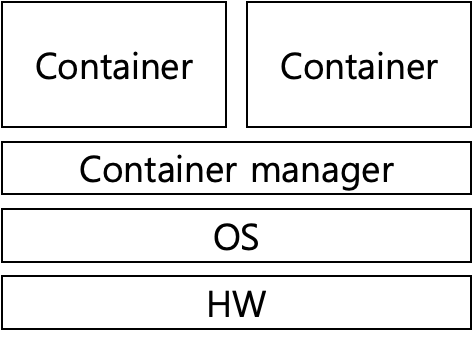
여기서 컨테이너(container)는 하나의 운영체제 커널에서 다른 프로세스에 영향을 받지 않고 독립적으로 실행되는 프로세스 상태를 의미합니다.
Fig 1. 컨테이너
모놀리식 아키텍처 vs 마이크로서비스 아키텍처
모놀리식 아키텍처(monolithic architecture)는 하나의 서비스 또는 어플리케이션에 여러 기능이 통합된 구조를 의미합니다.
반면 마이크로 서비스 아키텍처(microservices architecture)는 서비스가 하나의 목적을 지향한다는 점에서는 모놀리식 아키텍처와 동일하지만 각 개별기능들이 각각의 작은 서비스로 개발되는 모듈식 구조를 가집니다. 즉, 독립적으로 동작하는 작은 서비스들이 모여 하나의 전체를 이루고 있습니다.
모놀리식 아키텍처는 소프트웨어가 하나로 결합되어 있기 때문에 설계, 개발, 코드관리가 단순하고 간편하지만 수정 및 업데이트를 거칠 수록 전체 코드를 관리하여야 하기 때문에 유지보수에서 단점이 존재합니다. 마이크로 서비스 아키텍처의 경우 서비스가 모듈로 개발되기 때문에 재사용 및 유지보수에 유리한 장점이 있습니다. 하지만 개발에 있어 복잡도가 높으며 각각의 서비스 호출을 위한 네트워크 관리가 성능에 영향을 줄 수 있습니다.
컨테이너 인프라 환경은 일반적으로 마이크로서비스 아키텍처로 구현하기에 적합합니다. 컨테이너는 서비스 단위로 구현, 배포 및 확장에 용이하기 때문에 마이크로서비스 아키텍처의 서비스와 완벽하게 대응됩니다.
Fig2. 모놀리식 아키텍쳐와 마이크로서비스 아키텍처, AWS
도커
도커(docker)는 컨테이너를 만들고 관리하는 것을 도와주는 컨테이너 도구입니다. 도커로 컨테이너를 생성 및 제거할 수 있으며, 운영체제 환경에 관계없이 동리한 결과를 보장하는 장점이 있습니다.
쿠버네티스
쿠버네티스(kubernetes)는 다수의 컨테이너를 관리할 때 사용합니다. 특히, 컨테이너의 배포와 동작, 부하관리, 동적확장 등 다양한 기능을 자동화로 제공하기때문에 컨테이너 인프라에 필수적인 도구라고 할 수 있습니다.
젠킨스
젠킨스(jenkins)는 지속적 통합(continuous integration)과 지속적 배포(continuous deployment)를 지원합니다. 지속적 통합과 지속적 배포는 프로그램의 빌드, 테스트, 패키징, 배포 등의 단계를 모두 자동화해 표준화 합니다. 컨테이너 인프라는 단일기능을 빠르게 개발해 각 컨테이너로 적용해야하기 때문에, 마찬가지로 아주 유용한 도구입니다.
프로메테우스와 그라파나
프로메테우스(prometheus)는 인스턴스의 상태 데이터를 수집하고, 그라파나(grafana)는 이를 시각화합니다.